

راهنمای شروع هوش مصنوعی و یادگیری ماشین

بسیاری با هوش مصنوعی و کاربردهای آن آشنا هستند اما نمیدانند که چگونه باید شروع به یادگیری کنند و در این مسیر قدم بردارند. هوش مصنوعی دامنه وسیعی از مسائل و روشها را شامل میشود. اگر در این باره جستجو کرده باشید احتمالا با تعداد زیادی مقاله درباره روشهای یادگیری ماشین مثل شبکههای نورونی یا مسائل مطرح در هوش مصنوعی مثل دسته بندی دادهها، پیشبینی وقایع و ... روبهرو شدهاید. در اینجا قصد نداریم به تعریف کلمات و صرفا مثال بپردازیم چرا که تاکنون مقالات زیادی در این باره به زبان فارسی نوشته شدهاند. هدف از این نوشته، دستیابی به یک راهنما برای شروع یادگیری و کسب تخصص در این زمینه است.
بهتر است قبل از هر چیزی بدانیم که هوش مصنوعی چیزی به جز علم ریاضی و آمار نیست بنابراین قبل از این که بخواهید از انواع مختلف کتابخانههای موجود در زبانهای برنامهنویسی استفاده کنید و خودتان را در توابعی غرق کنید که فقط شما را گیجتر میکنند باید با اصول ریاضی و تئوریهای مرتبط آشنا شوید تا بتوانید درک خوبی از مسائل، راهحلها و کاربردهای آنها داشته باشید. اکنون بیایید با تابع رگرسیون شروع کنیم. یکی از مهمترین توابعی که پایه بسیاری از روشهای یادگیری ماشین است. احتمال فرمول تابع خطی را از دوران راهنمایی به یاد داشته باشید. این تابع در فضای دو بعدی یعنی صفحه، خطی راست ترسیم میکند.
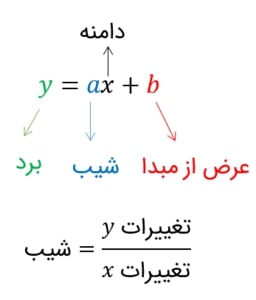
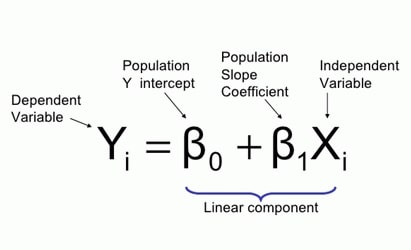
سادهترین نوع رگرسیون یعنی رگرسیون خطی کاملا مشابه تابع نشان داده شده در شکل بالا است. به شکل 2 دقت کنید. Beta0 همان عرض از مبدا و Beta1 همان شیب است. گاهی ممکن است متغیری به نام epsilon یا همان خطای تصادفی نمونه در این فرمول ببینید. اگر 10 دفعه دمای هوا را اندازه بگیرید احتمالا هر بار دماسنج مقدار متفاوتی را به شما نشان میدهد چون دماسنج صرفا یک وسیله است که دقت کامل ندارد. epsilon برای شبیهسازی این موضوع کاربرد دارد. اکنون که صحبت از نمونه شد اندیس i هم شماره نمونه را نشان میدهد. X2 یعنی ویژگیهای نمونه دوم که با استفاده از آن میتوان مقدار Y2 را محاسبه کرد. با این که متغیر X میتواند برداری چند بعدی باشد اما بیایید فعلا برای سادگی آن را یک عدد در نظر بگیریم. مثلا X میتواند قد افراد باشد و Y هم به وزن اشاره کند. یعنی قصد داریم با دانستن قد افراد، وزن آنها را تخمین بزنیم. روند انجام کار به شکل زیر است:
- پیدا کردن چند نمونه تمرینی که از قبل مقدار X و Y را برای آنها میدانیم.
- محاسبه Beta0 و Beta1 به نحوی که حداکثر دقت را در تخمین X به وسیله Y داشته باشد.
- اکنون که مقادیر Beta را محاسبه کرده ایم میتوانیم با استفاده از جمعآوری قد انسانها و قرار دادن آن به جای X وزن یا به عبارت دیگر Y را تخمین بزنیم.
ثابت میشود که برای محاسبه مقادیر Beta که در مرحله 2 یاد شد میتوان از فرمولهای شکل 3 استفاده کرد که در آن n تعداد نمونهها است. Sigma نمادی برای جمع جملات ، x bar میانگین x برای تمام نمونههای تمرینی جمعآوری شده در مرحله 1 و y bar هم به طریق مشابه نمایش دهنده میانگین است.
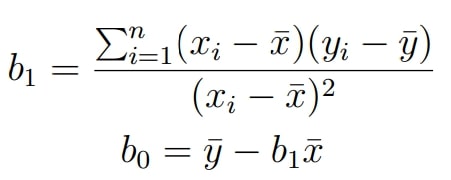
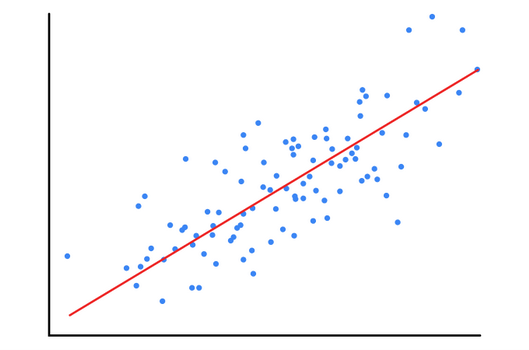
روندی که در این مقاله بررسی کردیم یادگیری نظارت شده نام دارد. یعنی این که با مشاهده تعدادی نمونه تمرینی مدل مورد نظر(در اینجا رگرسیون خطی) را تمرین میدهیم تا بتواند محاسبات لازم را برای نمونههای آینده انجام دهد. مثلا با دانستن قد، وزن را پیشبینی کند. شکل 4 یگ خط رگرسور را نشان میدهد که با استفاده از نمونههای مشاهده شده رسم گردیده است. با استفاده از این خط میتوانیم به ازای هر X، مقدار مورد انتظار Y را پیشبینی کنیم. هر چند که این مقادیر پیشبینی شده توسط رگرسور ممکن است با مقدارهای واقعی (نقاط آبی) کمی اختلاف داشته باشد.
اکنون که با کلیات تابع رگرسیون آشنا شدهاید مطالعه بیشتر درباره موضوعات زیر توصیه میگردد:
- رگرسیون با ابعاد بالاتر: متغیر X به شکل بردار
- جاسازی bias: حذف متغیر Beta0
- محاسبه تابع ضرر یا loss function: خطای تخمین برای یک نمونه
- خطای تصادفی یا random error: شبیهسازی خطای اندازهگیری
- رگرسیون خطی با دیدگاه احتمالاتی: حل مشکل خطای تصادفی
- ارزیابی دقت رگرسیون
- انواع غیر خطی رگرسیون